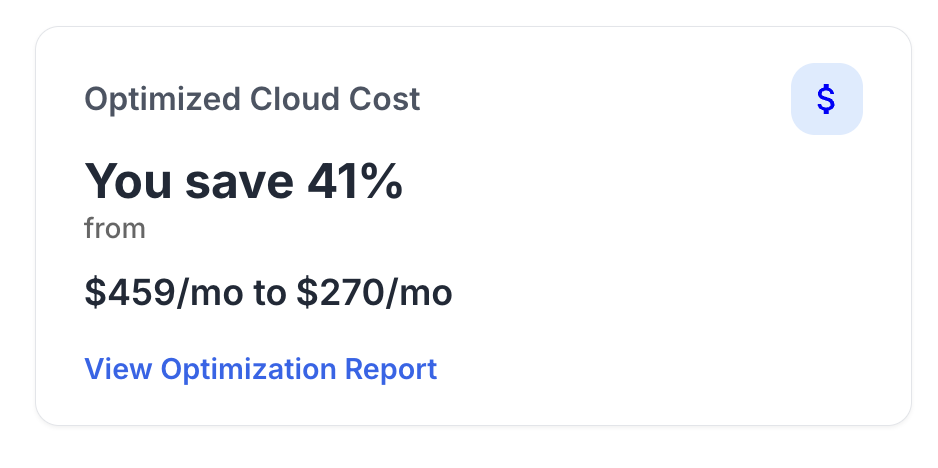
Cut Your LLM Costs by 70% Without Losing Accuracy
Most AI teams are paying 10× more than they need to. Our Small-Model Orchestrator automatically sends each request to the smallest, fastest model capable of handling it and only escalates when complexity demands it.
Trusted by thousands of companies





Built to Keep Accuracy - Not Break It
Our router constantly measures task complexity and confidence before sending a request. If uncertainty crosses a threshold, the system automatically escalates to GPT-class models.
Fast, Lightweight, and Transparent
Unlike “AI middle layers” that slow you down, our router adds increases speed instead. It’s the orchestration layer that’s actually built for production: auditable, visible, and fast.
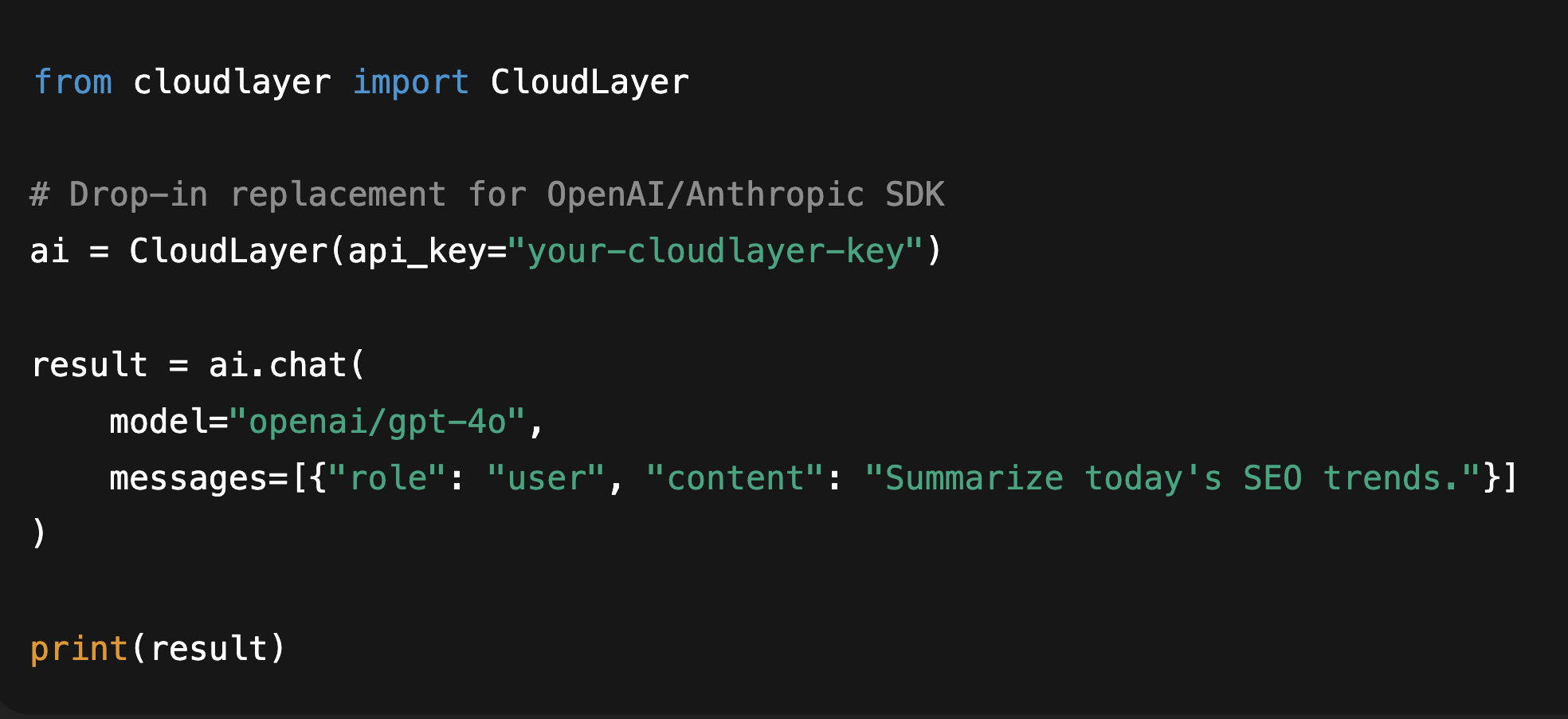
One-Line Integration, Zero Lock-In
Drop our SDK or API gateway in front of your existing model calls — no retraining, no vendor tie-in. It works with OpenAI, Anthropic, Mistral, and local models out of the box.
See the ROI Before You Join
Upload a sample of your recent prompt logs (or estimated usage) and our simulator shows how much you’d save if routed intelligently. Most teams cut token spend by 60-70 % while maintaining output parity.