




Our router constantly measures task complexity and confidence before sending a request.If uncertainty crosses a threshold, the system automatically escalates to GPT-class models.
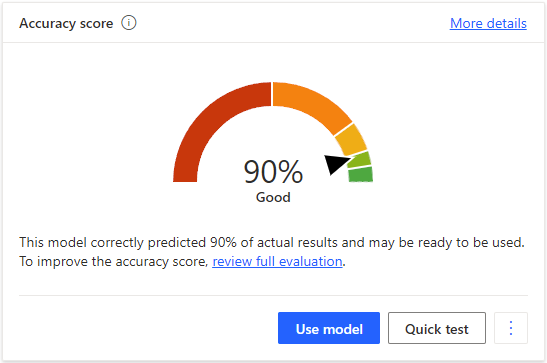
Unlike “AI middle layers” that slow you down, our router adds increases speed instead. It’s the orchestration layer that’s actually built for production: auditable, visible, and fast.
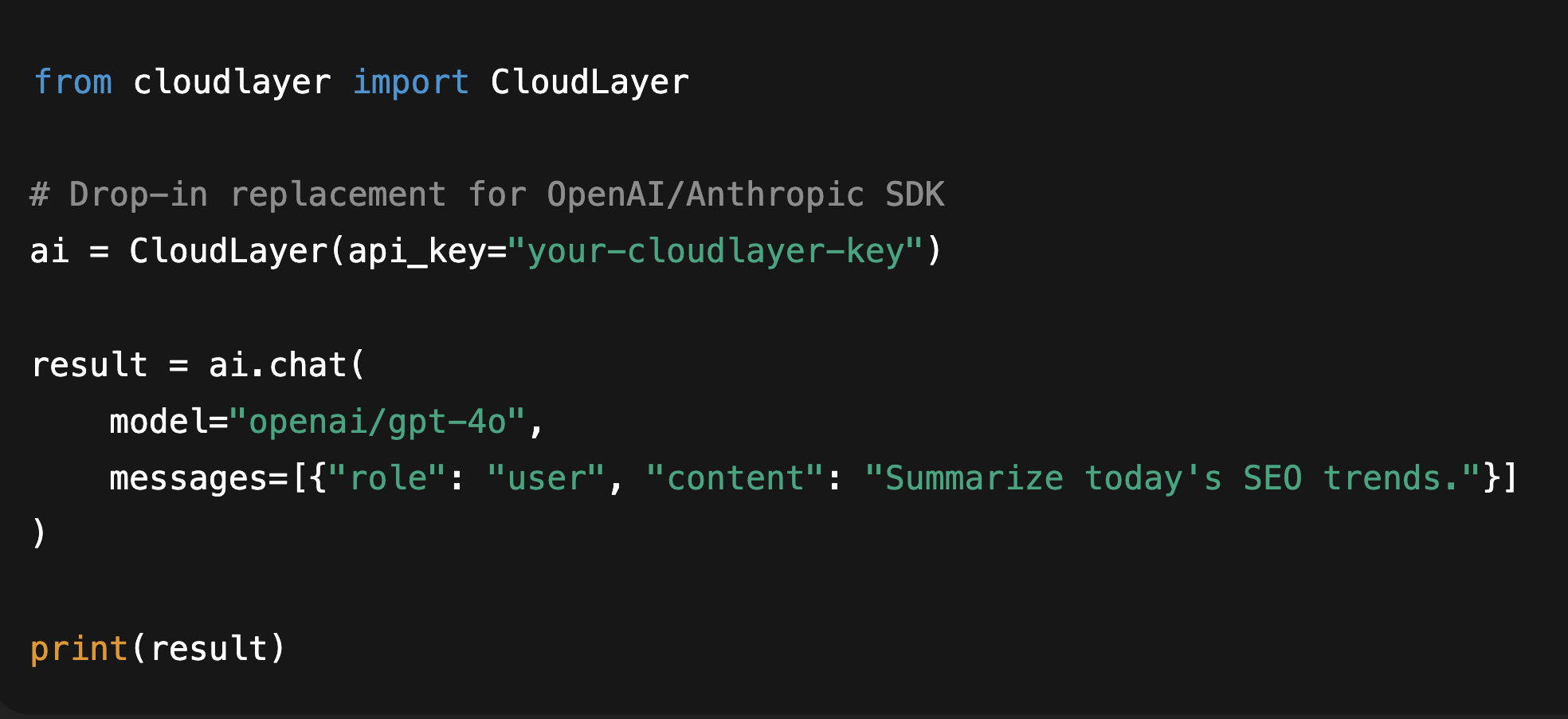
Drop our SDK or API gateway in front of your existing model calls — no retraining, no vendor tie-in.It works with OpenAI, Anthropic, Mistral, and local models out of the box.
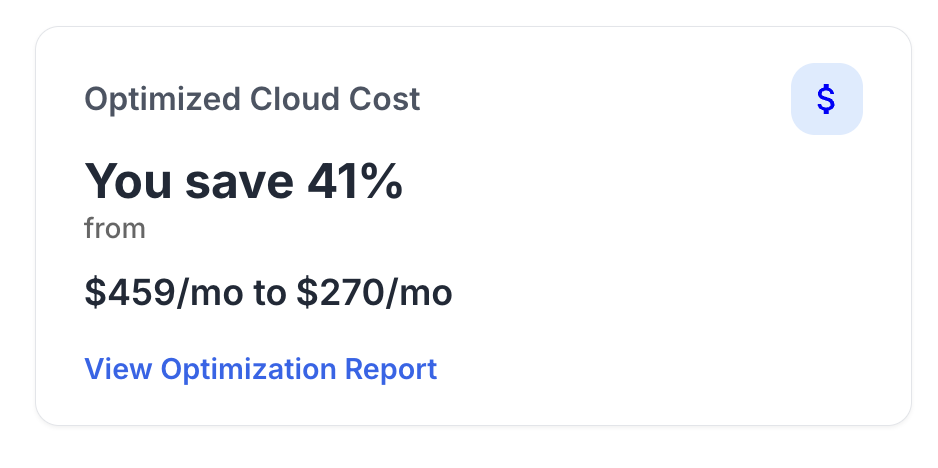
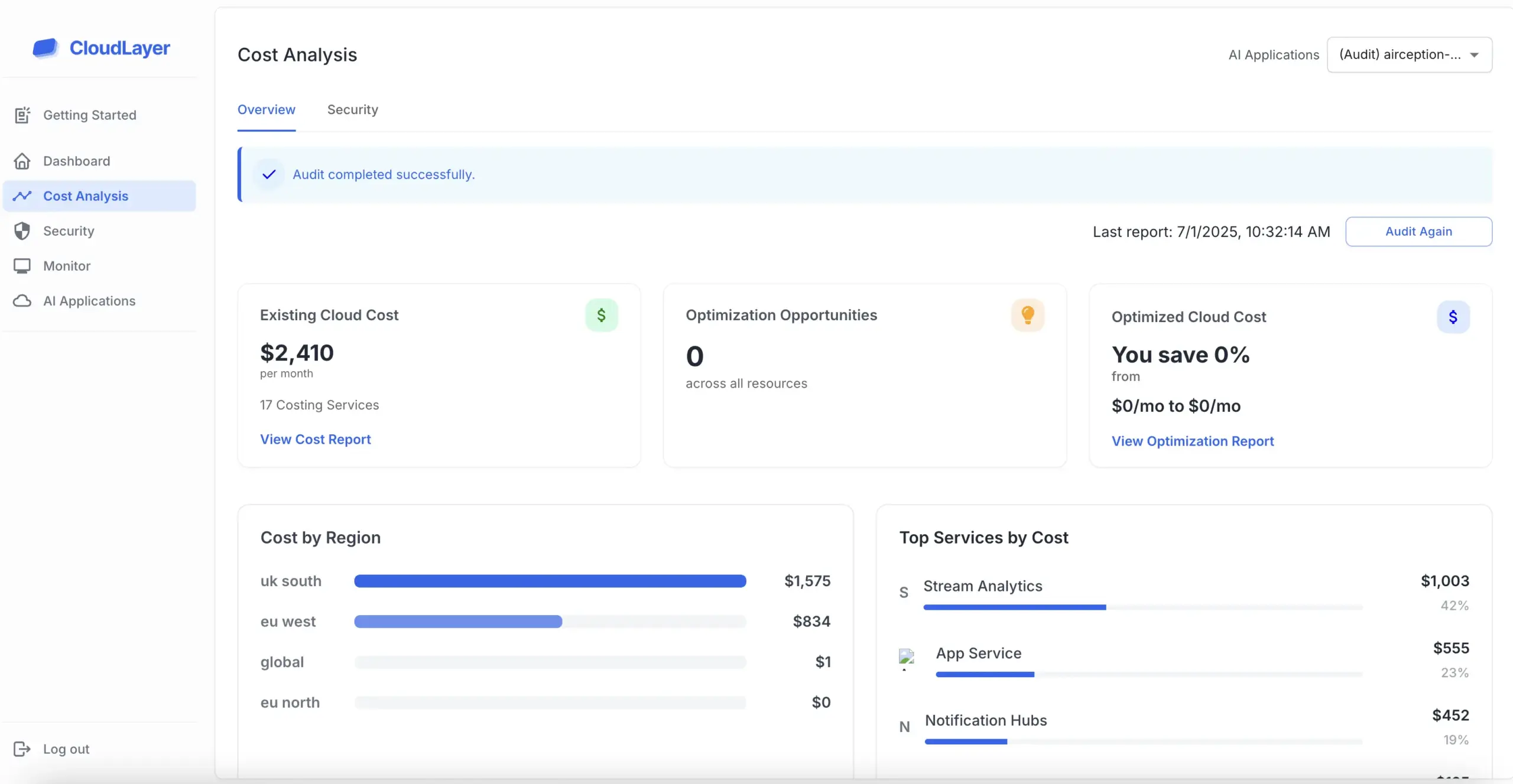
Upload a sample of your recent prompt logs (or estimated usage) and our simulator shows how much you’d save if routed intelligently.Most teams cut token spend by 60-70 % while maintaining output parity.